inches <- c(69, 62, 66, 70, 70, 73, 67, 73, 67, 70)This lecture, as the rest of the course, is adapted from the version Stephanie C. Hicks designed and maintained in 2021 and 2022. Check the recent changes to this file through the GitHub history.
Pre-lecture materials
Read ahead
NoteRead ahead
Before class, you can prepare by reading the following materials:
Acknowledgements
Material for this lecture was borrowed and adopted from
Learning objectives
NoteLearning objectives
At the end of this lesson you will:
- Understand how to perform vector arithmetics in R
- Implement the 5 functional loops in R (vs e.g. for loops) in R
Vectorization
Writing for and while loops are useful and easy to understand, but in R we rarely use them.
As you learn more R, you will realize that vectorization is preferred over for-loops since it results in shorter and clearer code.
Vector arithmetics
Rescaling a vector
In R, arithmetic operations on vectors occur element-wise. For a quick example, suppose we have height in inches:
and want to convert to centimeters.
Notice what happens when we multiply inches by 2.54:
inches * 2.54 [1] 175.26 157.48 167.64 177.80 177.80 185.42 170.18 185.42 170.18 177.80In the line above, we multiplied each element by 2.54.
Similarly, if for each entry we want to compute how many inches taller or shorter than 69 inches (the average height for males), we can subtract it from every entry like this:
inches - 69 [1] 0 -7 -3 1 1 4 -2 4 -2 1Two vectors
If we have two vectors of the same length, and we sum them in R, they will be added entry by entry as follows:
x <- 1:10
y <- 1:10
x + y [1] 2 4 6 8 10 12 14 16 18 20The same holds for other mathematical operations, such as -, * and /.
x <- 1:10
sqrt(x) [1] 1.000000 1.414214 1.732051 2.000000 2.236068 2.449490 2.645751 2.828427
[9] 3.000000 3.162278y <- 1:10
x * y [1] 1 4 9 16 25 36 49 64 81 100That is, we don’t write a for loop that takes each element of x and each element of y, adds, them up, then puts them all in a single vector.
## Check that x and y have the same length
stopifnot(length(x) == length(y))
## Create our result object
result <- vector(mode = "integer", length = length(x))
## Loop through each element of x and y, calculate the sum,
## then store it on 'result'
for (i in seq_along(x)) {
result[i] <- x[i] + y[i]
}
## Check that we got the same answer
identical(result, x + y)[1] TRUEFunctional loops
While for loops are perfectly valid, when you use vectorization in an element-wise fashion, there is no need for for loops because we can apply what are called functional loops.
Functional loops are functions that help us apply the same function to each entry in a vector, matrix, data frame, or list. Here are a list of them in base R:
lapply(): Loop over a list and evaluate a function on each elementsapply(): Same aslapplybut try to simplify the resultapply(): Apply a function over the margins of an arraytapply(): Apply a function over subsets of a vectormapply(): Multivariate version oflapply(won’t cover)
An auxiliary function split() is also useful, particularly in conjunction with lapply().
Define a function
my_sum <- function(a, b) {
a + b
}
## Same but with an extra check to make sure that 'a' and 'b'
## have the same lengths.
my_sum <- function(a, b) {
## Check that a and b are of the same length
stopifnot(length(a) == length(b))
a + b
}Apply your function
Here since we have two input vectors, we need to use mapply() which is one of the more complex functions. Note the weird order of the arguments where the function we will mapply() over comes before the inputs to said function.
## Check the arguments to mapply()
args(mapply)function (FUN, ..., MoreArgs = NULL, SIMPLIFY = TRUE, USE.NAMES = TRUE)
NULL## Apply mapply() to our function my_sum() with the inputs 'x' and 'y'
mapply(sum776::my_sum, x, y) [1] 2 4 6 8 10 12 14 16 18 20## Or write an anynymous function that is:
## * not documented
## * not tested
## * not shared
##
## :(
mapply(function(a, b) {
a + b
}, x, y) [1] 2 4 6 8 10 12 14 16 18 20purrr alternative
The purrr package, which is part of the tidyverse, provides an alternative framework to the apply family of functions in base R.

library("purrr") ## part of tidyverse## Check the arguments of map2_int()
args(purrr::map2_int)function (.x, .y, .f, ..., .progress = FALSE)
NULL## Apply our function my_sum() to our inputs
purrr::map2_int(x, y, sum776::my_sum) [1] 2 4 6 8 10 12 14 16 18 20## You can also use anonymous functions
purrr::map2_int(x, y, function(a, b) {
a + b
}) [1] 2 4 6 8 10 12 14 16 18 20## purrr even has a super short formula-like syntax
## where .x is the first input and .y is the second one
purrr::map2_int(x, y, ~ .x + .y) [1] 2 4 6 8 10 12 14 16 18 20## This formula syntax has nothing to do with the objects 'x' and 'y'
purrr::map2_int(1:2, 3:4, ~ .x + .y)[1] 4 6
Base R loops
lapply()
The lapply() function does the following simple series of operations:
- it loops over a list, iterating over each element in that list
- it applies a function to each element of the list (a function that you specify)
- and returns a list (the
linlapply()is for “list”).
This function takes three arguments: (1) a list X; (2) a function (or the name of a function) FUN; (3) other arguments via its ... argument. If X is not a list, it will be coerced to a list using as.list().
The body of the lapply() function can be seen here.
lapplyfunction (X, FUN, ...)
{
FUN <- match.fun(FUN)
if (!is.vector(X) || is.object(X))
X <- as.list(X)
.Internal(lapply(X, FUN))
}
<bytecode: 0x11f13b800>
<environment: namespace:base>
TipNote
The actual looping is done internally in C code for efficiency reasons.
It is important to remember that lapply() always returns a list, regardless of the class of the input.
TipExample
Here’s an example of applying the mean() function to all elements of a list. If the original list has names, the the names will be preserved in the output.
x <- list(a = 1:5, b = rnorm(10))
x$a
[1] 1 2 3 4 5
$b
[1] 1.74674240 0.61327895 0.07430473 0.42115141 -0.64381753 1.42263258
[7] 0.28278509 -0.15372358 0.22298620 0.23411131lapply(x, mean)$a
[1] 3
$b
[1] 0.4220452Notice that here we are passing the mean() function as an argument to the lapply() function.
purrr::map_dbl(x, mean) a b
3.0000000 0.4220452 What difference do you notice in terms of the output of lapply() and purrr::map_dbl()?
purrr::map(x, mean)$a
[1] 3
$b
[1] 0.4220452Functions in R can be used this way and can be passed back and forth as arguments just like any other object in R.
When you pass a function to another function, you do not need to include the open and closed parentheses () like you do when you are calling a function.
TipExample
Here is another example of using lapply().
x <- list(a = 1:4, b = rnorm(10), c = rnorm(20, 1), d = rnorm(100, 5))
lapply(x, mean)$a
[1] 2.5
$b
[1] 0.1018754
$c
[1] 1.175001
$d
[1] 5.067207You can use lapply() to evaluate a function multiple times each with a different argument.
Next is an example where I call the runif() function (to generate uniformly distributed random variables) four times, each time generating a different number of random numbers.
x <- 1:4
lapply(x, runif)[[1]]
[1] 0.9155942
[[2]]
[1] 0.602441604 0.005958148
[[3]]
[1] 0.3745703 0.4737332 0.1189540
[[4]]
[1] 0.53275194 0.02855169 0.47440699 0.61104526
TipWhat happened?
When you pass a function to lapply(), lapply() takes elements of the list and passes them as the first argument of the function you are applying.
In the above example, the first argument of runif() is n, and so the elements of the sequence 1:4 all got passed to the n argument of runif().
This also works with purrr functions.
purrr::map(x, runif)[[1]]
[1] 0.8648622
[[2]]
[1] 0.4445934 0.4638005
[[3]]
[1] 0.1732884 0.3674504 0.6362085
[[4]]
[1] 0.4247436 0.4139468 0.8514355 0.7666486Functions that you pass to lapply() may have other arguments. For example, the runif() function has a min and max argument too.
NoteQuestion
In the example above I used the default values for min and max.
- How would you be able to specify different values for that in the context of
lapply()?
Here is where the ... argument to lapply() comes into play. Any arguments that you place in the ... argument will get passed down to the function being applied to the elements of the list.
Here, the min = 0 and max = 10 arguments are passed down to runif() every time it gets called.
x <- 1:4
lapply(x, runif, min = 0, max = 10)[[1]]
[1] 5.62294
[[2]]
[1] 6.120768 6.683343
[[3]]
[1] 6.387056 4.371937 4.937801
[[4]]
[1] 9.680522 4.438564 3.734991 6.373060So now, instead of the random numbers being between 0 and 1 (the default), the are all between 0 and 10. Again, this also works with purrr functions.
purrr::map(x, runif, min = 0, max = 10)[[1]]
[1] 1.801176
[[2]]
[1] 7.973248 6.898636
[[3]]
[1] 5.3614468 1.4021785 0.3117477
[[4]]
[1] 7.1906605 4.8297006 0.3616360 0.3355722The lapply() function (and its friends) makes heavy use of anonymous functions. Anonymous functions are like members of Project Mayhem—they have no names. These functions are generated “on the fly” as you are using lapply(). Once the call to lapply() is finished, the function disappears and does not appear in the workspace.
TipExample
Here I am creating a list that contains two matrices.
x <- list(a = matrix(1:4, 2, 2), b = matrix(1:6, 3, 2))
x$a
[,1] [,2]
[1,] 1 3
[2,] 2 4
$b
[,1] [,2]
[1,] 1 4
[2,] 2 5
[3,] 3 6Suppose I wanted to extract the first column of each matrix in the list. I could write an anonymous function for extracting the first column of each matrix.
lapply(x, function(elt) {
elt[, 1]
})$a
[1] 1 2
$b
[1] 1 2 3Notice that I put the function() definition right in the call to lapply().
This is perfectly legal and acceptable. You can put an arbitrarily complicated function definition inside lapply(), but if it’s going to be more complicated, it’s probably a better idea to define the function separately.
For example, I could have done the following.
f <- function(elt) {
elt[, 1]
}
lapply(x, f)$a
[1] 1 2
$b
[1] 1 2 3
TipNote
Now the function is no longer anonymous; its name is f.
Whether you use an anonymous function or you define a function first depends on your context. If you think the function f is something you are going to need a lot in other parts of your code, you might want to define it separately. But if you are just going to use it for this call to lapply(), then it is probably simpler to use an anonymous function.
sapply()
The sapply() function behaves similarly to lapply(); the only real difference is in the return value. sapply() will try to simplify the result of lapply() if possible. Essentially, sapply() calls lapply() on its input and then applies the following algorithm:
If the result is a list where every element is length 1, then a vector is returned
If the result is a list where every element is a vector of the same length (> 1), a matrix is returned.
If it can’t figure things out, a list is returned
- This can be a source of many headaches and one of the main motivations behind the
purrrpackage. Withpurrryou know exactly what type of output you are getting!
- This can be a source of many headaches and one of the main motivations behind the
Here’s the result of calling lapply().
x <- list(a = 1:4, b = rnorm(10), c = rnorm(20, 1), d = rnorm(100, 5))
lapply(x, mean)$a
[1] 2.5
$b
[1] -0.0289228
$c
[1] 0.8240488
$d
[1] 5.089893Notice that lapply() returns a list (as usual), but that each element of the list has length 1.
Here’s the result of calling sapply() on the same list.
sapply(x, mean) a b c d
2.5000000 -0.0289228 0.8240488 5.0898927 Because the result of lapply() was a list where each element had length 1, sapply() collapsed the output into a numeric vector, which is often more useful than a list.
With purrr, if I want a list output, I use map(). If I want a double (numeric) output, we can use map_dbl().
purrr::map(x, mean)$a
[1] 2.5
$b
[1] -0.0289228
$c
[1] 0.8240488
$d
[1] 5.089893purrr::map_dbl(x, mean) a b c d
2.5000000 -0.0289228 0.8240488 5.0898927 split()
The split() function takes a vector or other objects and splits it into groups determined by a factor or list of factors.
The arguments to split() are
str(split)function (x, f, drop = FALSE, ...) where
xis a vector (or list) or data framefis a factor (or coerced to one) or a list of factorsdropindicates whether empty factors levels should be dropped
The combination of split() and a function like lapply() or sapply() is a common paradigm in R. The basic idea is that you can take a data structure, split it into subsets defined by another variable, and apply a function over those subsets. The results of applying that function over the subsets are then collated and returned as an object. This sequence of operations is sometimes referred to as “map-reduce” in other contexts.
Here we simulate some data and split it according to a factor variable. Note that we use the gl() function to “generate levels” in a factor variable.
x <- c(rnorm(10), runif(10), rnorm(10, 1))
f <- gl(3, 10) # generate factor levels
f [1] 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 3 3 3 3 3 3 3 3 3 3
Levels: 1 2 3split(x, f)$`1`
[1] 0.036889250 0.439156242 -0.171449018 0.268308762 -0.005784603
[6] -0.037474725 0.571768648 -0.509378178 -2.206236031 -0.622883084
$`2`
[1] 0.4008668 0.2120854 0.9700646 0.7878063 0.6285846 0.1459494 0.9827753
[8] 0.4098482 0.1778611 0.4292090
$`3`
[1] -0.73843715 -0.11862435 1.13214158 0.82010277 0.55687342 -0.07636030
[7] 2.45904045 0.57225537 0.02053563 0.44537470A common idiom is split followed by an lapply.
lapply(split(x, f), mean)$`1`
[1] -0.2237083
$`2`
[1] 0.5145051
$`3`
[1] 0.5072902Splitting a Data Frame
library("datasets")
head(airquality) Ozone Solar.R Wind Temp Month Day
1 41 190 7.4 67 5 1
2 36 118 8.0 72 5 2
3 12 149 12.6 74 5 3
4 18 313 11.5 62 5 4
5 NA NA 14.3 56 5 5
6 28 NA 14.9 66 5 6We can split the airquality data frame by the Month variable so that we have separate sub-data frames for each month.
s <- split(airquality, airquality$Month)
str(s)List of 5
$ 5:'data.frame': 31 obs. of 6 variables:
..$ Ozone : int [1:31] 41 36 12 18 NA 28 23 19 8 NA ...
..$ Solar.R: int [1:31] 190 118 149 313 NA NA 299 99 19 194 ...
..$ Wind : num [1:31] 7.4 8 12.6 11.5 14.3 14.9 8.6 13.8 20.1 8.6 ...
..$ Temp : int [1:31] 67 72 74 62 56 66 65 59 61 69 ...
..$ Month : int [1:31] 5 5 5 5 5 5 5 5 5 5 ...
..$ Day : int [1:31] 1 2 3 4 5 6 7 8 9 10 ...
$ 6:'data.frame': 30 obs. of 6 variables:
..$ Ozone : int [1:30] NA NA NA NA NA NA 29 NA 71 39 ...
..$ Solar.R: int [1:30] 286 287 242 186 220 264 127 273 291 323 ...
..$ Wind : num [1:30] 8.6 9.7 16.1 9.2 8.6 14.3 9.7 6.9 13.8 11.5 ...
..$ Temp : int [1:30] 78 74 67 84 85 79 82 87 90 87 ...
..$ Month : int [1:30] 6 6 6 6 6 6 6 6 6 6 ...
..$ Day : int [1:30] 1 2 3 4 5 6 7 8 9 10 ...
$ 7:'data.frame': 31 obs. of 6 variables:
..$ Ozone : int [1:31] 135 49 32 NA 64 40 77 97 97 85 ...
..$ Solar.R: int [1:31] 269 248 236 101 175 314 276 267 272 175 ...
..$ Wind : num [1:31] 4.1 9.2 9.2 10.9 4.6 10.9 5.1 6.3 5.7 7.4 ...
..$ Temp : int [1:31] 84 85 81 84 83 83 88 92 92 89 ...
..$ Month : int [1:31] 7 7 7 7 7 7 7 7 7 7 ...
..$ Day : int [1:31] 1 2 3 4 5 6 7 8 9 10 ...
$ 8:'data.frame': 31 obs. of 6 variables:
..$ Ozone : int [1:31] 39 9 16 78 35 66 122 89 110 NA ...
..$ Solar.R: int [1:31] 83 24 77 NA NA NA 255 229 207 222 ...
..$ Wind : num [1:31] 6.9 13.8 7.4 6.9 7.4 4.6 4 10.3 8 8.6 ...
..$ Temp : int [1:31] 81 81 82 86 85 87 89 90 90 92 ...
..$ Month : int [1:31] 8 8 8 8 8 8 8 8 8 8 ...
..$ Day : int [1:31] 1 2 3 4 5 6 7 8 9 10 ...
$ 9:'data.frame': 30 obs. of 6 variables:
..$ Ozone : int [1:30] 96 78 73 91 47 32 20 23 21 24 ...
..$ Solar.R: int [1:30] 167 197 183 189 95 92 252 220 230 259 ...
..$ Wind : num [1:30] 6.9 5.1 2.8 4.6 7.4 15.5 10.9 10.3 10.9 9.7 ...
..$ Temp : int [1:30] 91 92 93 93 87 84 80 78 75 73 ...
..$ Month : int [1:30] 9 9 9 9 9 9 9 9 9 9 ...
..$ Day : int [1:30] 1 2 3 4 5 6 7 8 9 10 ...Then we can take the column means for Ozone, Solar.R, and Wind for each sub-data frame.
lapply(s, function(x) {
colMeans(x[, c("Ozone", "Solar.R", "Wind")])
})$`5`
Ozone Solar.R Wind
NA NA 11.62258
$`6`
Ozone Solar.R Wind
NA 190.16667 10.26667
$`7`
Ozone Solar.R Wind
NA 216.483871 8.941935
$`8`
Ozone Solar.R Wind
NA NA 8.793548
$`9`
Ozone Solar.R Wind
NA 167.4333 10.1800 Using sapply() might be better here for a more readable output.
sapply(s, function(x) {
colMeans(x[, c("Ozone", "Solar.R", "Wind")])
}) 5 6 7 8 9
Ozone NA NA NA NA NA
Solar.R NA 190.16667 216.483871 NA 167.4333
Wind 11.62258 10.26667 8.941935 8.793548 10.1800Unfortunately, there are NAs in the data so we cannot simply take the means of those variables. However, we can tell the colMeans function to remove the NAs before computing the mean.
sapply(s, function(x) {
colMeans(x[, c("Ozone", "Solar.R", "Wind")],
na.rm = TRUE
)
}) 5 6 7 8 9
Ozone 23.61538 29.44444 59.115385 59.961538 31.44828
Solar.R 181.29630 190.16667 216.483871 171.857143 167.43333
Wind 11.62258 10.26667 8.941935 8.793548 10.18000We can also do this with purrr as shown below.
purrr::map(s, function(x) {
colMeans(x[, c("Ozone", "Solar.R", "Wind")], na.rm = TRUE)
})$`5`
Ozone Solar.R Wind
23.61538 181.29630 11.62258
$`6`
Ozone Solar.R Wind
29.44444 190.16667 10.26667
$`7`
Ozone Solar.R Wind
59.115385 216.483871 8.941935
$`8`
Ozone Solar.R Wind
59.961538 171.857143 8.793548
$`9`
Ozone Solar.R Wind
31.44828 167.43333 10.18000 The above is not as condensed as the sapply() output. We can use the superseded (aka no longer supported) function map_dfc():
purrr::map_dfc(s, function(x) {
colMeans(x[, c("Ozone", "Solar.R", "Wind")], na.rm = TRUE)
})# A tibble: 3 × 5
`5` `6` `7` `8` `9`
<dbl> <dbl> <dbl> <dbl> <dbl>
1 23.6 29.4 59.1 60.0 31.4
2 181. 190. 216. 172. 167.
3 11.6 10.3 8.94 8.79 10.2Or use the currently supported function purrr::list_cbind(). Though we also need to do a bit more work behind the scenes.
## Make sure we get data.frame / tibble outputs for each element
## of the list
purrr:::map(s, function(x) {
tibble::as_tibble(colMeans(x[, c("Ozone", "Solar.R", "Wind")], na.rm = TRUE))
})$`5`
# A tibble: 3 × 1
value
<dbl>
1 23.6
2 181.
3 11.6
$`6`
# A tibble: 3 × 1
value
<dbl>
1 29.4
2 190.
3 10.3
$`7`
# A tibble: 3 × 1
value
<dbl>
1 59.1
2 216.
3 8.94
$`8`
# A tibble: 3 × 1
value
<dbl>
1 60.0
2 172.
3 8.79
$`9`
# A tibble: 3 × 1
value
<dbl>
1 31.4
2 167.
3 10.2## Now we can combine them with list_cbind()
purrr:::map(s, function(x) {
tibble::as_tibble(colMeans(x[, c("Ozone", "Solar.R", "Wind")], na.rm = TRUE))
}) %>% purrr::list_cbind()# A tibble: 3 × 5
`5`$value `6`$value `7`$value `8`$value `9`$value
<dbl> <dbl> <dbl> <dbl> <dbl>
1 23.6 29.4 59.1 60.0 31.4
2 181. 190. 216. 172. 167.
3 11.6 10.3 8.94 8.79 10.2## And we can then add the actual variable it came from with mutate()
purrr:::map(s, function(x) {
tibble::as_tibble(colMeans(x[, c("Ozone", "Solar.R", "Wind")], na.rm = TRUE))
}) %>%
purrr::list_cbind() %>%
dplyr::mutate(Variable = c("Ozone", "Solar.R", "Wind"))# A tibble: 3 × 6
`5`$value `6`$value `7`$value `8`$value `9`$value Variable
<dbl> <dbl> <dbl> <dbl> <dbl> <chr>
1 23.6 29.4 59.1 60.0 31.4 Ozone
2 181. 190. 216. 172. 167. Solar.R
3 11.6 10.3 8.94 8.79 10.2 Wind As we know, the above output is not tidy.
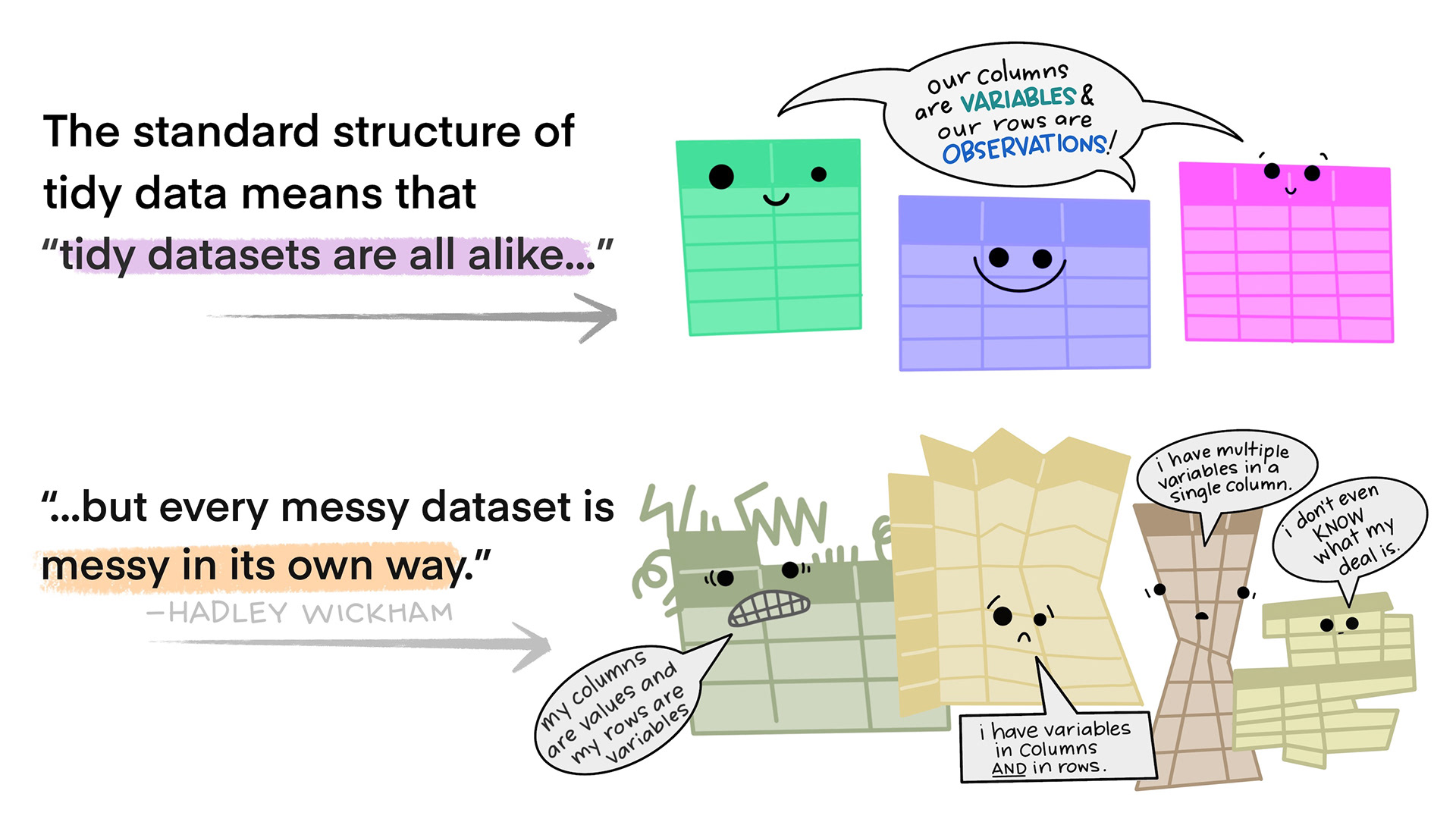
So below we repeat the steps using similar functions. First we use the superseded map_dfr() function. At https://purrr.tidyverse.org/reference/map_dfr.html we can find more details about why this function was superseded and what that means.
## Sadly map_dfr() is now superseded (aka not recommended)
purrr:::map_dfr(s, function(x) {
colMeans(x[, c("Ozone", "Solar.R", "Wind")], na.rm = TRUE)
})# A tibble: 5 × 3
Ozone Solar.R Wind
<dbl> <dbl> <dbl>
1 23.6 181. 11.6
2 29.4 190. 10.3
3 59.1 216. 8.94
4 60.0 172. 8.79
5 31.4 167. 10.2 ## This is how we would have added back the Month variable
purrr:::map_dfr(s, function(x) {
colMeans(x[, c("Ozone", "Solar.R", "Wind")], na.rm = TRUE)
}) %>%
dplyr:::mutate(Month = as.integer(names(s)))# A tibble: 5 × 4
Ozone Solar.R Wind Month
<dbl> <dbl> <dbl> <int>
1 23.6 181. 11.6 5
2 29.4 190. 10.3 6
3 59.1 216. 8.94 7
4 60.0 172. 8.79 8
5 31.4 167. 10.2 9Instead, we’ll use the t() function for transposing a vector and purrr:list_rbind().
## Get data.frame / tibble outputs, but with each variable as a separate
## column. Here we used the t() or transpose() function.
purrr:::map(s, function(x) {
tibble::as_tibble(t(colMeans(x[, c("Ozone", "Solar.R", "Wind")], na.rm = TRUE)))
})$`5`
# A tibble: 1 × 3
Ozone Solar.R Wind
<dbl> <dbl> <dbl>
1 23.6 181. 11.6
$`6`
# A tibble: 1 × 3
Ozone Solar.R Wind
<dbl> <dbl> <dbl>
1 29.4 190. 10.3
$`7`
# A tibble: 1 × 3
Ozone Solar.R Wind
<dbl> <dbl> <dbl>
1 59.1 216. 8.94
$`8`
# A tibble: 1 × 3
Ozone Solar.R Wind
<dbl> <dbl> <dbl>
1 60.0 172. 8.79
$`9`
# A tibble: 1 × 3
Ozone Solar.R Wind
<dbl> <dbl> <dbl>
1 31.4 167. 10.2## Now we can row bind each of these data.frames / tibbles into a
## single one
purrr:::map(s, function(x) {
tibble::as_tibble(t(colMeans(x[, c("Ozone", "Solar.R", "Wind")], na.rm = TRUE)))
}) %>% purrr::list_rbind()# A tibble: 5 × 3
Ozone Solar.R Wind
<dbl> <dbl> <dbl>
1 23.6 181. 11.6
2 29.4 190. 10.3
3 59.1 216. 8.94
4 60.0 172. 8.79
5 31.4 167. 10.2 ## Then with mutate, we can add the Month back
purrr:::map(s, function(x) {
tibble::as_tibble(t(colMeans(x[, c("Ozone", "Solar.R", "Wind")], na.rm = TRUE)))
}) %>%
purrr::list_rbind() %>%
dplyr:::mutate(Month = as.integer(names(s)))# A tibble: 5 × 4
Ozone Solar.R Wind Month
<dbl> <dbl> <dbl> <int>
1 23.6 181. 11.6 5
2 29.4 190. 10.3 6
3 59.1 216. 8.94 7
4 60.0 172. 8.79 8
5 31.4 167. 10.2 9For the above task though, we might prefer to use dplyr functions.
## group_by() is in a way splitting our input data.frame / tibble by
## our variable of interest. Then summarize() helps us specify how we
## want to use that data, before it's all put back together into a
## tidy tibble.
airquality %>%
dplyr::group_by(Month) %>%
dplyr::summarize(
Ozone = mean(Ozone, na.rm = TRUE),
Solar.R = mean(Solar.R, na.rm = TRUE),
Wind = mean(Wind, na.rm = TRUE)
)# A tibble: 5 × 4
Month Ozone Solar.R Wind
<int> <dbl> <dbl> <dbl>
1 5 23.6 181. 11.6
2 6 29.4 190. 10.3
3 7 59.1 216. 8.94
4 8 60.0 172. 8.79
5 9 31.4 167. 10.2 tapply
tapply() is used to apply a function over subsets of a vector. It can be thought of as a combination of split() and sapply() for vectors only. I’ve been told that the “t” in tapply() refers to “table”, but that is unconfirmed.
str(tapply)function (X, INDEX, FUN = NULL, ..., default = NA, simplify = TRUE) The arguments to tapply() are as follows:
Xis a vectorINDEXis a factor or a list of factors (or else they are coerced to factors)FUNis a function to be applied- … contains other arguments to be passed
FUN simplify, should we simplify the result?
TipExample
Given a vector of numbers, one simple operation is to take group means.
## Simulate some data
x <- c(rnorm(10), runif(10), rnorm(10, 1))
## Define some groups with a factor variable
f <- gl(3, 10)
f [1] 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 3 3 3 3 3 3 3 3 3 3
Levels: 1 2 3tapply(x, f, mean) 1 2 3
0.008496425 0.434576502 1.051060161 We can also apply functions that return more than a single value. In this case, tapply() will not simplify the result and will return a list. Here’s an example of finding the range() (min and max) of each sub-group.
tapply(x, f, range)$`1`
[1] -1.35972 1.39826
$`2`
[1] 0.08806992 0.92058272
$`3`
[1] -0.1887393 3.0773427With purrr, we don’t have a tapply() direct equivalent but we can still get similar results thanks to the split() function.
split(x, f) %>% purrr::map_dbl(mean) 1 2 3
0.008496425 0.434576502 1.051060161 split(x, f) %>% purrr::map(range)$`1`
[1] -1.35972 1.39826
$`2`
[1] 0.08806992 0.92058272
$`3`
[1] -0.1887393 3.0773427apply()
The apply() function is used to a evaluate a function (often an anonymous one) over the margins of an array. It is most often used to apply a function to the rows or columns of a matrix (which is just a 2-dimensional array). However, it can be used with general arrays, for example, to take the average of an array of matrices. Using apply() is not really faster than writing a loop, but it works in one line and is highly compact.
str(apply)function (X, MARGIN, FUN, ..., simplify = TRUE) The arguments to apply() are
Xis an arrayMARGINis an integer vector indicating which margins should be “retained”.FUNis a function to be applied...is for other arguments to be passed toFUN
TipExample
Here I create a 20 by 10 matrix of Normal random numbers. I then compute the mean of each column.
x <- matrix(rnorm(200), 20, 10)
head(x) [,1] [,2] [,3] [,4] [,5] [,6]
[1,] 0.50046809 0.01319246 -1.2257339 0.6534950 2.0240798 -0.5110592
[2,] -0.97947352 -0.74034878 -0.7333293 0.0852587 0.9646342 1.0375407
[3,] -0.76175904 -0.78276570 -1.3256824 0.5074134 -0.5256627 -1.8718745
[4,] -0.05374418 1.40241236 -1.1572989 0.4923247 1.1692155 1.2495283
[5,] 0.21665370 2.49795506 1.0303902 0.1020464 0.7384473 0.6245013
[6,] 0.21451380 -1.58611504 -0.3422167 0.5026345 -1.0660648 0.2152146
[,7] [,8] [,9] [,10]
[1,] 3.0450395 0.4156979 -1.5711215 1.16470122
[2,] -1.1407109 -1.3683067 -0.8307222 -0.01687646
[3,] -0.9718256 0.6301801 0.2372567 0.27668133
[4,] 0.8450216 -1.2188740 -0.7058502 -0.65473690
[5,] 0.7673133 0.3547224 1.3843766 -0.84345422
[6,] 0.6824437 0.3520303 0.5901982 -0.52446529apply(x, 2, mean) ## Take the mean of each column [1] -0.01626919 0.10659913 -0.31981647 0.09469021 0.30397538 -0.16036582
[7] 0.39368026 -0.13370231 -0.12090136 0.04522372
TipExample
I can also compute the sum of each row.
apply(x, 1, sum) ## Take the mean of each row [1] 4.5087595 -3.7223342 -4.5880384 1.3679983 6.8729520 -0.9618265
[7] 0.3539245 3.6576807 2.3910655 -1.8471082 1.9953436 -6.0260360
[13] -6.2214171 -0.1334884 -0.9813945 0.6822732 5.7145910 -3.5023396
[19] 5.2571158 -0.9554501
TipNote
In both calls to apply(), the return value was a vector of numbers.
You’ve probably noticed that the second argument is either a 1 or a 2, depending on whether we want row statistics or column statistics. What exactly is the second argument to apply()?
The MARGIN argument essentially indicates to apply() which dimension of the array you want to preserve or retain.
So when taking the mean of each column, I specify
apply(x, 2, mean)because I want to collapse the first dimension (the rows) by taking the mean and I want to preserve the number of columns. Similarly, when I want the row sums, I run
apply(x, 1, sum)because I want to collapse the columns (the second dimension) and preserve the number of rows (the first dimension).
With purrr this is a bit more complicated as it has been generalized. Matrices are arrays with 2 dimensions (margins), but they can have more. Here we use the array_branch() function to change x into a list, then use regular map_*() functions to compute what we want.
array_branch(x, 2) %>% map_dbl(mean) [1] -0.01626919 0.10659913 -0.31981647 0.09469021 0.30397538 -0.16036582
[7] 0.39368026 -0.13370231 -0.12090136 0.04522372array_branch(x, 1) %>% map_dbl(sum) [1] 4.5087595 -3.7223342 -4.5880384 1.3679983 6.8729520 -0.9618265
[7] 0.3539245 3.6576807 2.3910655 -1.8471082 1.9953436 -6.0260360
[13] -6.2214171 -0.1334884 -0.9813945 0.6822732 5.7145910 -3.5023396
[19] 5.2571158 -0.9554501Col/Row Sums and Means
TipPro-tip
For the special case of column/row sums and column/row means of matrices, we have some useful shortcuts.
rowSums=apply(x, 1, sum)rowMeans=apply(x, 1, mean)colSums=apply(x, 2, sum)colMeans=apply(x, 2, mean)
The shortcut functions are heavily optimized and hence are much faster, but you probably won’t notice unless you’re using a large matrix.
Another nice aspect of these functions is that they are a bit more descriptive. It’s arguably more clear to write colMeans(x) in your code than apply(x, 2, mean).
Other Ways to Apply
You can do more than take sums and means with the apply() function.
TipExample
For example, you can compute quantiles of the rows of a matrix using the quantile() function.
x <- matrix(rnorm(200), 20, 10)
head(x) [,1] [,2] [,3] [,4] [,5] [,6]
[1,] 0.8558389 1.2785114 -1.1288694 0.3338215 1.6094488 -0.22610146
[2,] -0.2651168 0.9989627 -0.9657882 -0.2079840 2.8384617 -0.07137058
[3,] -0.1270123 0.2804062 0.2954063 -0.6753049 1.6021894 -0.04851862
[4,] 0.3901520 -0.3279092 -0.2545932 0.7519181 1.4313260 -1.87021854
[5,] 0.1027492 -0.2221477 -0.2716407 0.6181248 -1.1347917 0.66075218
[6,] -0.6223277 0.5674514 0.2159777 -0.3270915 -0.2631378 -0.02378593
[,7] [,8] [,9] [,10]
[1,] 0.2544274 -0.192036937 -0.6799559 0.6865429
[2,] -0.3435362 -0.005259005 -0.6227724 -2.0137902
[3,] 1.1365090 -0.774514378 0.2140942 0.3998026
[4,] 0.2192841 -0.291010481 1.0355954 -1.2352538
[5,] 0.3817243 -0.968810389 0.3682024 -1.9738577
[6,] -0.3255215 -1.031961178 -1.1926808 -0.5793324## Get row quantiles
apply(x, 1, quantile, probs = c(0.25, 0.75)) [,1] [,2] [,3] [,4] [,5] [,6] [,7]
25% -0.2175853 -0.5529634 -0.1073889 -0.3186845 -0.7945180 -0.6115789 -1.222741
75% 0.8135149 -0.0217869 0.3737035 0.6614765 0.3783438 -0.0836239 1.109337
[,8] [,9] [,10] [,11] [,12] [,13]
25% -0.6131110 -0.7269225 0.01274949 -0.06737453 -0.6219057 -0.948169094
75% 0.4474504 0.4613348 0.41963659 1.18111557 0.3751943 0.006215612
[,14] [,15] [,16] [,17] [,18] [,19]
25% -0.1027043 -1.4287004 -0.2514263 -0.7535182 -0.7057536 -0.2993755
75% 0.6071806 0.2703042 0.4057326 0.1918586 0.2537656 0.2507634
[,20]
25% -0.5239071
75% 0.5436785Notice that I had to pass the probs = c(0.25, 0.75) argument to quantile() via the ... argument to apply().
array_branch(x, 1) %>%
map(quantile, probs = c(0.25, 0.75)) %>%
map(~ as.data.frame(t(.x))) %>%
list_rbind() 25% 75%
1 -0.21758533 0.813514883
2 -0.55296337 -0.021786899
3 -0.10738885 0.373703518
4 -0.31868455 0.661476538
5 -0.79451797 0.378343841
6 -0.61157890 -0.083623902
7 -1.22274071 1.109337157
8 -0.61311097 0.447450354
9 -0.72692253 0.461334754
10 0.01274949 0.419636588
11 -0.06737453 1.181115568
12 -0.62190573 0.375194348
13 -0.94816909 0.006215612
14 -0.10270429 0.607180553
15 -1.42870045 0.270304169
16 -0.25142633 0.405732633
17 -0.75351818 0.191858582
18 -0.70575359 0.253765591
19 -0.29937550 0.250763397
20 -0.52390708 0.543678487Vectorizing a Function
Let’s talk about how we can “vectorize” a function.
What this means is that we can write function that typically only takes single arguments and create a new function that can take vector arguments.
This is often needed when you want to plot functions.
TipExample
Here’s an example of a function that computes the sum of squares given some data, a mean parameter and a standard deviation. The formula is \(\sum_{i=1}^n(x_i-\mu)^2/\sigma^2\).
sumsq <- function(mu, sigma, x) {
sum(((x - mu) / sigma)^2)
}This function takes a mean mu, a standard deviation sigma, and some data in a vector x.
In many statistical applications, we want to minimize the sum of squares to find the optimal mu and sigma. Before we do that, we may want to evaluate or plot the function for many different values of mu or sigma.
x <- rnorm(100) ## Generate some data
sumsq(mu = 1, sigma = 1, x) ## This works (returns one value)[1] 222.3181However, passing a vector of mus or sigmas won’t work with this function because it’s not vectorized.
sumsq(1:10, 1:10, x) ## This is not what we want[1] 108.6111There’s even a function in R called Vectorize() that automatically can create a vectorized version of your function.
So we could create a vsumsq() function that is fully vectorized as follows.
vsumsq <- Vectorize(sumsq, c("mu", "sigma"))
vsumsq(1:10, 1:10, x) [1] 222.3181 135.4636 117.9323 111.3079 108.0185 106.1111 104.8885 104.0480
[9] 103.4396 102.9814## The details are a bit complicated though
## as we can see below
vsumsqfunction (mu, sigma, x)
{
args <- lapply(as.list(match.call())[-1L], eval, parent.frame())
names <- names(args) %||% character(length(args))
dovec <- names %in% vectorize.args
do.call("mapply", c(FUN = FUN, args[dovec], MoreArgs = list(args[!dovec]),
SIMPLIFY = SIMPLIFY, USE.NAMES = USE.NAMES))
}
<environment: 0x1284014f8>Pretty cool, right?
Parallelize your functions
We don’t have time to dive into the details, but with furrr we can parallelize purrr functions thanks to the future package. More details at https://furrr.futureverse.org/.
Similarly, with BiocParallel::bplapply() we can parallelize lapply() commands. Details at https://bioconductor.org/packages/release/bioc/vignettes/BiocParallel/inst/doc/Introduction_To_BiocParallel.html and more generally at https://bioconductor.org/packages/BiocParallel/.
Summary
The loop functions in R are very powerful because they allow you to conduct a series of operations on data using a compact form
The operation of a loop function involves iterating over an R object (e.g. a list or vector or matrix), applying a function to each element of the object, and the collating the results and returning the collated results.
Loop functions make heavy use of anonymous functions, which exist for the life of the loop function but are not stored anywhere
The
split()function can be used to divide an R object in to subsets determined by another variable which can subsequently be looped over using loop functions.With
purrryou have very tight control on the expected output, unlike with base R.
Post-lecture materials
Final Questions
Here are some post-lecture questions to help you think about the material discussed.
NoteQuestions
- Write a function
compute_s_n()that for any givenncomputes the sum
\[ S_n = 1^2 + 2^2 + 3^2 + \ldots + n^2 \]
Report the value of the sum when \(n\) = 10.
Define an empty numerical vector
s_nof size 25 usings_n <- vector("numeric", 25)and store in the results of \(S_1, S_2, \ldots, S_n\) using a for-loop.Repeat Q3, but this time use
sapply() or functions frompurrr.Plot
s_nversusn. Use points defined by \(n= 1, \ldots, 25\)
Additional Resources
R session information
options(width = 120)
sessioninfo::session_info()─ Session info ───────────────────────────────────────────────────────────────────────────────────────────────────────
setting value
version R version 4.5.1 (2025-06-13)
os macOS Sequoia 15.6.1
system aarch64, darwin20
ui X11
language (EN)
collate en_US.UTF-8
ctype en_US.UTF-8
tz America/New_York
date 2025-09-22
pandoc 3.7.0.2 @ /opt/homebrew/bin/ (via rmarkdown)
quarto 1.4.550 @ /Applications/quarto/bin/quarto
─ Packages ───────────────────────────────────────────────────────────────────────────────────────────────────────────
package * version date (UTC) lib source
brio 1.1.5 2024-04-24 [1] CRAN (R 4.5.0)
cli 3.6.5 2025-04-23 [1] CRAN (R 4.5.0)
colorout * 1.3-2 2025-05-09 [1] Github (jalvesaq/colorout@572ab10)
desc 1.4.3 2023-12-10 [1] CRAN (R 4.5.0)
digest 0.6.37 2024-08-19 [1] CRAN (R 4.5.0)
dplyr 1.1.4 2023-11-17 [1] CRAN (R 4.5.0)
evaluate 1.0.5 2025-08-27 [1] CRAN (R 4.5.0)
fastmap 1.2.0 2024-05-15 [1] CRAN (R 4.5.0)
generics 0.1.4 2025-05-09 [1] CRAN (R 4.5.0)
glue 1.8.0 2024-09-30 [1] CRAN (R 4.5.0)
htmltools 0.5.8.1 2024-04-04 [1] CRAN (R 4.5.0)
htmlwidgets 1.6.4 2023-12-06 [1] CRAN (R 4.5.0)
jsonlite 2.0.0 2025-03-27 [1] CRAN (R 4.5.0)
knitr 1.50 2025-03-16 [1] CRAN (R 4.5.0)
lifecycle 1.0.4 2023-11-07 [1] CRAN (R 4.5.0)
magrittr 2.0.4 2025-09-12 [1] CRAN (R 4.5.0)
pillar 1.11.1 2025-09-17 [1] CRAN (R 4.5.0)
pkgconfig 2.0.3 2019-09-22 [1] CRAN (R 4.5.0)
pkgload 1.4.0 2024-06-28 [1] CRAN (R 4.5.0)
purrr * 1.1.0 2025-07-10 [1] CRAN (R 4.5.0)
R6 2.6.1 2025-02-15 [1] CRAN (R 4.5.0)
rlang 1.1.6 2025-04-11 [1] CRAN (R 4.5.0)
rmarkdown 2.29 2024-11-04 [1] CRAN (R 4.5.0)
rprojroot 2.1.1 2025-08-26 [1] CRAN (R 4.5.0)
sessioninfo 1.2.3 2025-02-05 [1] CRAN (R 4.5.0)
sum776 0.99.0 2025-09-22 [1] Github (lcolladotor/sum776@fa92a67)
testthat * 3.2.3 2025-01-13 [1] CRAN (R 4.5.0)
tibble 3.3.0 2025-06-08 [1] CRAN (R 4.5.0)
tidyselect 1.2.1 2024-03-11 [1] CRAN (R 4.5.0)
utf8 1.2.6 2025-06-08 [1] CRAN (R 4.5.0)
vctrs 0.6.5 2023-12-01 [1] CRAN (R 4.5.0)
waldo 0.6.2 2025-07-11 [1] CRAN (R 4.5.0)
withr 3.0.2 2024-10-28 [1] CRAN (R 4.5.0)
xfun 0.53 2025-08-19 [1] CRAN (R 4.5.0)
yaml 2.3.10 2024-07-26 [1] CRAN (R 4.5.0)
[1] /Library/Frameworks/R.framework/Versions/4.5-arm64/Resources/library
* ── Packages attached to the search path.
──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────