## Install the tidyverse package if you don't have it
if (!require("tidyverse", quietly = TRUE)) {
install.packages("tidyverse")
}Project 1
project 1
projects
Finding great chocolate bars!
This project, as the rest of the course, is adapted from the version Stephanie C. Hicks designed and maintained in 2021 and 2022. Check the recent changes to this file through the GitHub history.
Background
Due date: September 14th at 11:59pm
To submit your project
Please write up your project using R Markdown and knitr. Compile your document as an HTML file and submit your HTML file to the dropbox on Courseplus. Please show all your code for each of the answers to each part.
To get started, watch this video on setting up your R Markdown document.
Install tidyverse
Before attempting this assignment, you should first install the tidyverse package if you have not already. The tidyverse package is actually a collection of many packages that serves as a convenient way to install many packages without having to do them one by one. This can be done with the install.packages() function.
Running this function will install a host of other packages so it make take a minute or two depending on how fast your computer is. Once you have installed it, you will want to load the package.
library("tidyverse")Data
That data for this part of the assignment comes from TidyTuesday, which is a weekly podcast and global community activity brought to you by the R4DS Online Learning Community. The goal of TidyTuesday is to help R learners learn in real-world contexts.
![]()
[Source: TidyTuesday]
{kind=link}
If we look at the TidyTuesday github repo from 2022, we see this dataset chocolate bar reviews.
To access the data, you need to install the tidytuesdayR R package and use the function tt_load() with the date of ‘2022-01-18’ to load the data.
## Install the tidytuesdayR package if you don't have it
if (!require("tidytuesdayR", quietly = TRUE)) {
install.packages("tidytuesdayR")
}
## For the GitHub version of tidytuesdayR (in case the CRAN version is not available)
## you'll need the "remotes" package to install it.
## See for example https://github.com/dslc-io/tidytuesdayR/issues/94 which led
## to tidytuesdayR not been available from CRAN at the end of August 2024
## Install the remotes package if you don't have it
if (!require("remotes", quietly = TRUE)) {
install.packages("remotes")
}
## Install the tidytuesdayR package (from GitHub) if you don't have it
if (!require("tidytuesdayR", quietly = TRUE)) {
remotes::install_github("dslc-io/tidytuesdayR")
}This is how you can download the data.
tuesdata <- tidytuesdayR::tt_load("2022-01-18")
chocolate <- tuesdata$chocolateHowever, if you use this code, you will hit an API limit after trying to compile the document a few times. Instead, I suggest you use the following code below. Here, I provide the code below for you to avoid re-downloading data:
library("here")
library("tidyverse")
# tests if a directory named "data" exists locally
if (!dir.exists(here("data"))) {
dir.create(here("data"))
}
# saves data only once (not each time you knit a R Markdown)
if (!file.exists(here("data", "chocolate.RDS"))) {
url_csv <- "https://raw.githubusercontent.com/rfordatascience/tidytuesday/main/data/2022/2022-01-18/chocolate.csv"
chocolate <- readr::read_csv(url_csv)
# save the file to RDS objects
saveRDS(chocolate, file = here("data", "chocolate.RDS"))
}Here we read in the .RDS dataset locally from our computing environment:
chocolate <- readRDS(here("data", "chocolate.RDS"))
as_tibble(chocolate)# A tibble: 2,530 × 10
ref company_manufacturer company_location review_date
<dbl> <chr> <chr> <dbl>
1 2454 5150 U.S.A. 2019
2 2458 5150 U.S.A. 2019
3 2454 5150 U.S.A. 2019
4 2542 5150 U.S.A. 2021
5 2546 5150 U.S.A. 2021
6 2546 5150 U.S.A. 2021
7 2542 5150 U.S.A. 2021
8 797 A. Morin France 2012
9 797 A. Morin France 2012
10 1011 A. Morin France 2013
# ℹ 2,520 more rows
# ℹ 6 more variables: country_of_bean_origin <chr>,
# specific_bean_origin_or_bar_name <chr>, cocoa_percent <chr>,
# ingredients <chr>, most_memorable_characteristics <chr>, rating <dbl>We can take a glimpse at the data
glimpse(chocolate)Rows: 2,530
Columns: 10
$ ref <dbl> 2454, 2458, 2454, 2542, 2546, 2546, 2…
$ company_manufacturer <chr> "5150", "5150", "5150", "5150", "5150…
$ company_location <chr> "U.S.A.", "U.S.A.", "U.S.A.", "U.S.A.…
$ review_date <dbl> 2019, 2019, 2019, 2021, 2021, 2021, 2…
$ country_of_bean_origin <chr> "Tanzania", "Dominican Republic", "Ma…
$ specific_bean_origin_or_bar_name <chr> "Kokoa Kamili, batch 1", "Zorzal, bat…
$ cocoa_percent <chr> "76%", "76%", "76%", "68%", "72%", "8…
$ ingredients <chr> "3- B,S,C", "3- B,S,C", "3- B,S,C", "…
$ most_memorable_characteristics <chr> "rich cocoa, fatty, bready", "cocoa, …
$ rating <dbl> 3.25, 3.50, 3.75, 3.00, 3.00, 3.25, 3…Here is a data dictionary for what all the column names mean:
Part 1: Explore data
In this part, use functions from dplyr and ggplot2 to answer the following questions.
- Make a histogram of the
ratingscores to visualize the overall distribution of scores. Change the number of bins from the default to 10, 15, 20, and 25 1. Pick on the one that you think looks the best. Explain what the difference is when you change the number of bins and explain why you picked the one you did.
# Add your solution here and describe your answer afterwardsThe ratings are discrete values making the histogram look strange. When you make the bin size smaller, it aggregates the ratings together in larger groups removing that effect. I picked 15, but there really is no wrong answer. Just looking for an answer here.
- Consider the countries where the beans originated from. How many reviews come from each country of bean origin?
# Add your solution here- What is average
ratingscores from reviews of chocolate bars that have Ecuador ascountry_of_bean_originin this dataset? For this same set of reviews, also calculate (1) the total number of reviews and (2) the standard deviation of theratingscores. Your answer should be a new data frame with these three summary statistics in three columns. Label the name of these columnsmean,sd, andtotal.
# Add your solution here- Which company location makes the best chocolate (or has the highest ratings on average) with beans from Ecuador?
# Add your solution here- Calculate the average rating across all country of origins for beans. Which top 3 countries (for bean origin) have the highest ratings on average?
# Add your solution here- Following up on the previous problem, now remove any countries of bean origins that have less than 10 chocolate bar reviews. Now, which top 3 countries have the highest ratings on average?
# Add your solution here- For this last part, let’s explore the relationship between percent chocolate and ratings.
Use the functions in dplyr, tidyr, and lubridate to perform the following steps to the chocolate dataset:
- Identify the countries of bean origin with at least 50 reviews. Remove reviews from countries are not in this list.
- Using the variable describing the chocolate percentage for each review, create a new column that groups chocolate percentages into one of four groups: (i) <60%, (ii) >=60 to <70%, (iii) >=70 to <90%, and (iii) >=90% (Hint check out the
substr()function in base R and thecase_when()function fromdplyr– see example below). - Using the new column described in #2, re-order the factor levels (if needed) to be starting with the smallest percentage group and increasing to the largest percentage group (Hint check out the
fct_relevel()function fromforcats). - For each country, make a set of four side-by-side boxplots plotting the groups on the x-axis and the ratings on the y-axis. These plots should be faceted by country.
On average, which category of chocolate percentage is most highly rated? Do these countries mostly agree or are there disagreements?
Hint: You may find the case_when() function useful in this part, which can be used to map values from one variable to different values in a new variable (when used in a mutate() call).
## Generate some random numbers
dat <- tibble(x = rnorm(100))
slice(dat, 1:3)# A tibble: 3 × 1
x
<dbl>
1 -0.300
2 -0.291
3 -1.04 ## Create a new column that indicates whether the value of 'x' is positive or negative
dat %>%
mutate(is_positive = case_when(
x >= 0 ~ "Yes",
x < 0 ~ "No"
))# A tibble: 100 × 2
x is_positive
<dbl> <chr>
1 -0.300 No
2 -0.291 No
3 -1.04 No
4 -0.673 No
5 -0.667 No
6 -0.905 No
7 1.06 Yes
8 0.131 Yes
9 -0.499 No
10 -0.0179 No
# ℹ 90 more rows# Add your solution herePart 2: Join two datasets together
The goal of this part of the assignment is to join two datasets together. gapminder is a R package that contains an excerpt from the Gapminder data (use the unfiltered version!).
Tasks
- Use this dataset it to create a new column called
continentin ourchocolatedataset2 that contains the continent name for each review where the country of bean origin is. - Only keep reviews that have reviews from countries of bean origin with at least 10 reviews.
- Also, remove the country of bean origin named
"Blend". - Make a set of violin plots with ratings on the y-axis and
continents on the x-axis.
Hint:
- Check to see if there are any
NAs in the new column. If there are anyNAs, add the continent name for each row.
# Add your solution herePart 3: Convert wide data into long data
The goal of this part of the assignment is to take a dataset that is either messy or simply not tidy and to make them tidy datasets. The objective is to gain some familiarity with the functions in the dplyr, tidyr packages. You may find it helpful to review the section on pivoting data from wide to long format and vice versa.
Tasks
We are going to create a set of features for us to plot over time. Use the functions in dplyr and tidyr to perform the following steps to the chocolate dataset:
- Create a new set of columns titled
beans,sugar,cocoa_butter,vanilla,letchin, andsaltthat contain a 1 or 0 representing whether or not that review for the chocolate bar contained that ingredient (1) or not (0).- See this public gist for how to differentiate
SvsS*vsSausingstr_detect()from thestringrpackage.
- See this public gist for how to differentiate
- Create a new set of columns titled
char_cocoa,char_sweet,char_nutty,char_creamy,char_roasty,char_earthythat contain a 1 or 0 representing whether or not that the most memorable characteristic for the chocolate bar had that word (1) or not (0). For example, if the word “sweet” appears in themost_memorable_characteristics, then record a 1, otherwise a 0 for that review in thechar_sweetcolumn (Hint: check outstr_detect()from thestringrpackage). - For each year (i.e.
review_date), calculate the mean value in each new column you created across all reviews for that year. (Hint: If all has gone well thus far, you should have a dataset with 16 rows and 13 columns). - Convert this wide dataset into a long dataset with a new
featureandmean_scorecolumn.
It should look something like this:
review_date feature mean_score
<dbl> <chr> <dbl>
2006 beans 0.967741935
2006 sugar 0.967741935
2006 cocoa_butter 0.903225806
2006 vanilla 0.693548387
2006 letchin 0.693548387
2006 salt 0.000000000
2006 char_cocoa 0.209677419
2006 char_sweet 0.161290323
2006 char_nutty 0.032258065
2006 char_creamy 0.241935484 Notes
You may need to use functions outside these packages to obtain this result.
Do not worry about the ordering of the rows or columns. Depending on whether you use
gather()orpivot_longer(), the order of your output may differ from what is printed above. As long as the result is a tidy data set, that is sufficient.
# Add your solution herePart 4: Data visualization
In this part of the project, we will continue to work with our now tidy song dataset from the previous part.
Tasks
Use the functions in ggplot2 package to make a scatter plot of the mean_scores (y-axis) over time (x-axis). There should be one plot (facet) for each feature. For full credit, your plot should include:
- An overall title for the plot and a subtitle summarizing key trends that you found. Also include a caption in the figure with your name.
- Both the observed points for the
mean_score, but also a smoothed non-linear pattern of the trend - All plots should be shown in the one figure
- There should be an informative x-axis and y-axis label
Consider playing around with the theme() function to make the figure shine, including playing with background colors, font, etc. See https://github.com/lcolladotor/jhustatcomputing/issues/4 for an example on how you can choose colors if you have too many categories.
Notes
You may need to use functions outside these packages to obtain this result.
Don’t worry about the ordering of the rows or columns. Depending on whether you use
gather()orpivot_longer(), the order of your output may differ from what is printed above. As long as the result is a tidy data set, that is sufficient.
# Add your solution herePart 5: Make the worst plot you can!
This sounds a bit crazy I know, but I want this to try and be FUN! Instead of trying to make a “good” plot, I want you to explore your creative side and make a really awful data visualization in every way. :)
Tasks
Using the chocolate dataset (or any of the modified versions you made throughout this assignment or anything else you wish you build upon it):
- Make the absolute worst plot that you can. You need to customize it in at least 7 ways to make it awful.
- In your document, write 1 - 2 sentences about each different customization you added (using bullets – i.e. there should be at least 7 bullet points each with 1-2 sentences), and how it could be useful for you when you want to make an awesome data visualization.
# Add your solution herePart 6: Make my plot a better plot!
The goal is to take my sad looking plot and make it better!
chocolate %>%
ggplot(aes(
x = as.factor(review_date),
y = rating,
fill = review_date
)) +
geom_violin()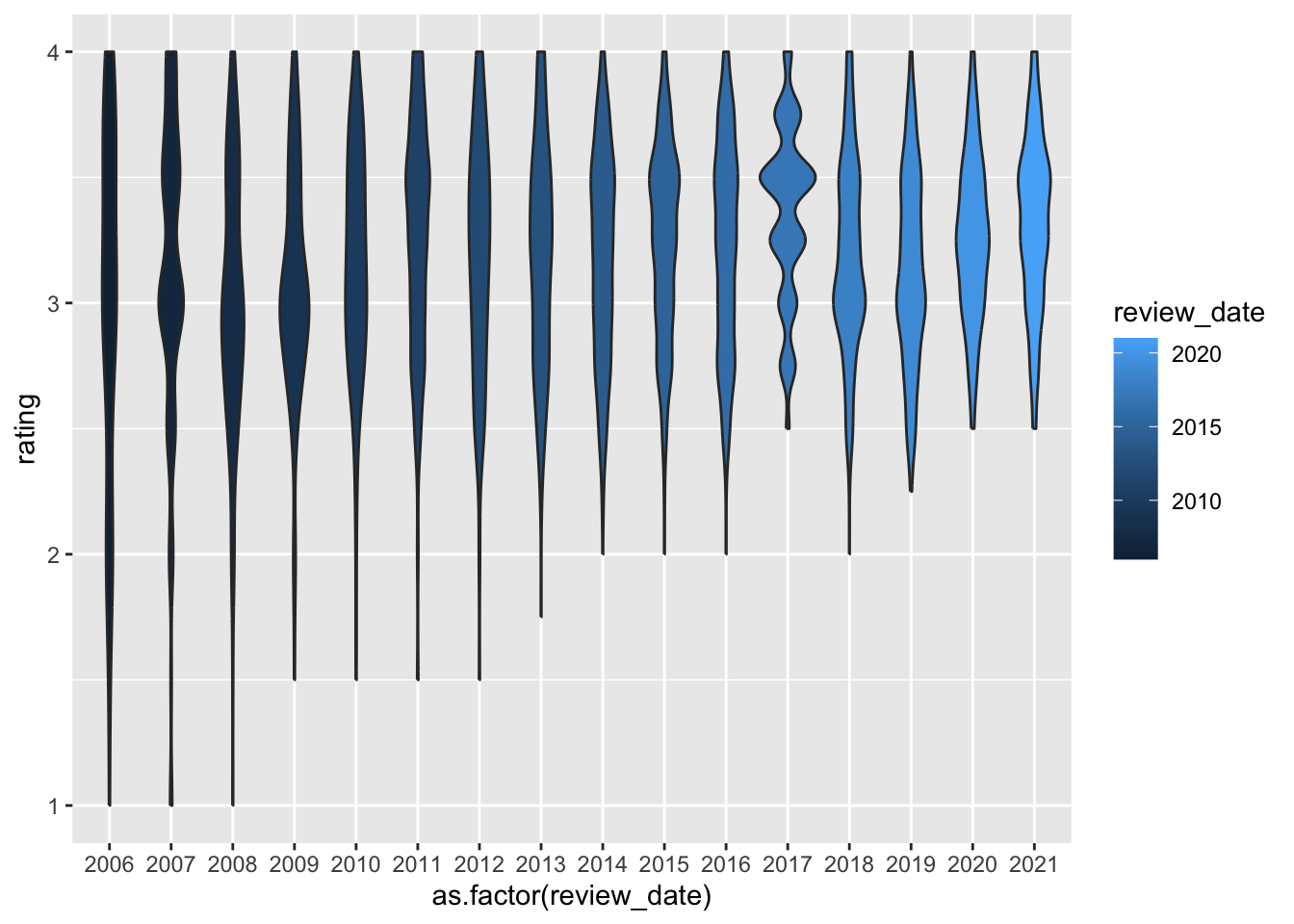
Tasks
- You need to customize it in at least 7 ways to make it better.
- In your document, write 1 - 2 sentences about each different customization you added (using bullets – i.e. there should be at least 7 bullet points each with 1-2 sentences), describing how you improved it.
# Add your solution hereR session information
options(width = 120)
sessioninfo::session_info()─ Session info ───────────────────────────────────────────────────────────────────────────────────────────────────────
setting value
version R version 4.5.1 (2025-06-13)
os macOS Sequoia 15.6.1
system aarch64, darwin20
ui X11
language (EN)
collate en_US.UTF-8
ctype en_US.UTF-8
tz America/New_York
date 2025-09-29
pandoc 3.7.0.2 @ /opt/homebrew/bin/ (via rmarkdown)
quarto 1.4.550 @ /Applications/quarto/bin/quarto
─ Packages ───────────────────────────────────────────────────────────────────────────────────────────────────────────
package * version date (UTC) lib source
cli 3.6.5 2025-04-23 [1] CRAN (R 4.5.0)
colorout * 1.3-2 2025-05-09 [1] Github (jalvesaq/colorout@572ab10)
dichromat 2.0-0.1 2022-05-02 [1] CRAN (R 4.5.0)
digest 0.6.37 2024-08-19 [1] CRAN (R 4.5.0)
dplyr * 1.1.4 2023-11-17 [1] CRAN (R 4.5.0)
evaluate 1.0.5 2025-08-27 [1] CRAN (R 4.5.0)
farver 2.1.2 2024-05-13 [1] CRAN (R 4.5.0)
fastmap 1.2.0 2024-05-15 [1] CRAN (R 4.5.0)
forcats * 1.0.1 2025-09-25 [1] CRAN (R 4.5.0)
generics 0.1.4 2025-05-09 [1] CRAN (R 4.5.0)
ggplot2 * 4.0.0 2025-09-11 [1] CRAN (R 4.5.0)
glue 1.8.0 2024-09-30 [1] CRAN (R 4.5.0)
gtable 0.3.6 2024-10-25 [1] CRAN (R 4.5.0)
here * 1.0.2 2025-09-15 [1] CRAN (R 4.5.0)
hms 1.1.3 2023-03-21 [1] CRAN (R 4.5.0)
htmltools 0.5.8.1 2024-04-04 [1] CRAN (R 4.5.0)
htmlwidgets 1.6.4 2023-12-06 [1] CRAN (R 4.5.0)
jsonlite 2.0.0 2025-03-27 [1] CRAN (R 4.5.0)
knitr 1.50 2025-03-16 [1] CRAN (R 4.5.0)
labeling 0.4.3 2023-08-29 [1] CRAN (R 4.5.0)
lifecycle 1.0.4 2023-11-07 [1] CRAN (R 4.5.0)
lubridate * 1.9.4 2024-12-08 [1] CRAN (R 4.5.0)
magrittr 2.0.4 2025-09-12 [1] CRAN (R 4.5.0)
pillar 1.11.1 2025-09-17 [1] CRAN (R 4.5.0)
pkgconfig 2.0.3 2019-09-22 [1] CRAN (R 4.5.0)
purrr * 1.1.0 2025-07-10 [1] CRAN (R 4.5.0)
R6 2.6.1 2025-02-15 [1] CRAN (R 4.5.0)
RColorBrewer 1.1-3 2022-04-03 [1] CRAN (R 4.5.0)
readr * 2.1.5 2024-01-10 [1] CRAN (R 4.5.0)
rlang 1.1.6 2025-04-11 [1] CRAN (R 4.5.0)
rmarkdown 2.29 2024-11-04 [1] CRAN (R 4.5.0)
rprojroot 2.1.1 2025-08-26 [1] CRAN (R 4.5.0)
S7 0.2.0 2024-11-07 [1] CRAN (R 4.5.0)
scales 1.4.0 2025-04-24 [1] CRAN (R 4.5.0)
sessioninfo 1.2.3 2025-02-05 [1] CRAN (R 4.5.0)
stringi 1.8.7 2025-03-27 [1] CRAN (R 4.5.0)
stringr * 1.5.2 2025-09-08 [1] CRAN (R 4.5.0)
tibble * 3.3.0 2025-06-08 [1] CRAN (R 4.5.0)
tidyr * 1.3.1 2024-01-24 [1] CRAN (R 4.5.0)
tidyselect 1.2.1 2024-03-11 [1] CRAN (R 4.5.0)
tidyverse * 2.0.0 2023-02-22 [1] CRAN (R 4.5.0)
timechange 0.3.0 2024-01-18 [1] CRAN (R 4.5.0)
tzdb 0.5.0 2025-03-15 [1] CRAN (R 4.5.0)
utf8 1.2.6 2025-06-08 [1] CRAN (R 4.5.0)
vctrs 0.6.5 2023-12-01 [1] CRAN (R 4.5.0)
withr 3.0.2 2024-10-28 [1] CRAN (R 4.5.0)
xfun 0.53 2025-08-19 [1] CRAN (R 4.5.0)
yaml 2.3.10 2024-07-26 [1] CRAN (R 4.5.0)
[1] /Library/Frameworks/R.framework/Versions/4.5-arm64/Resources/library
* ── Packages attached to the search path.
──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────