Benchmark of cellular deconvolution methods using a multi-assay reference dataset from postmortem human prefrontal cortex
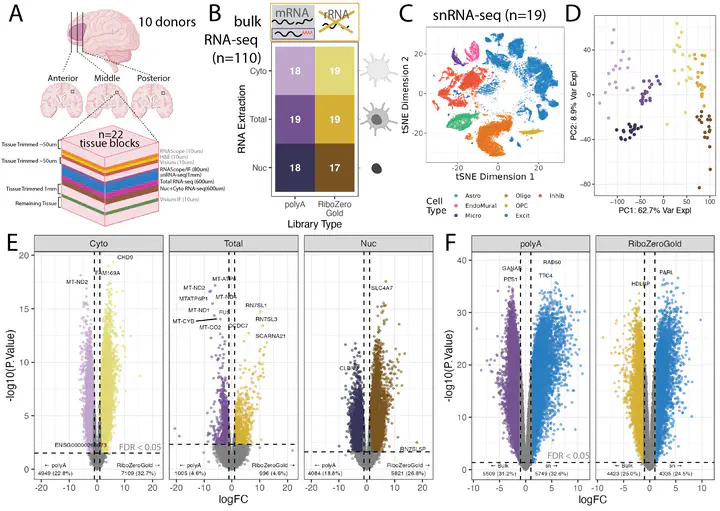 Image credit: bioRxiv
Image credit: bioRxiv
Abstract
Background Cellular deconvolution of bulk RNA-sequencing (RNA-seq) data using single cell or nuclei RNA-seq (sc/snRNA-seq) reference data is an important strategy for estimating cell type composition in heterogeneous tissues, such as human brain. Computational methods for deconvolution have been developed and benchmarked against simulated data, pseudobulked sc/snRNA-seq data, or immunohistochemistry reference data. A major limitation in developing improved deconvolution algorithms has been the lack of integrated datasets with orthogonal measurements of gene expression and estimates of cell type proportions on the same tissue sample. Deconvolution algorithm performance has not yet been evaluated across different RNA extraction methods (cytosolic, nuclear, or whole cell RNA), different library preparation types (mRNA enrichment vs. ribosomal RNA depletion), or with matched single cell reference datasets. Results A rich multi-assay dataset was generated in postmortem human dorsolateral prefrontal cortex (DLPFC) from 22 tissue blocks. Assays included spatially-resolved transcriptomics, snRNA-seq, bulk RNA-seq (across six library/extraction RNA-seq combinations), and RNAScope/Immunofluorescence (RNAScope/IF) for six broad cell types. The Mean Ratio method, implemented in the DeconvoBuddies R package, was developed for selecting cell type marker genes. Six computational deconvolution algorithms were evaluated in DLPFC and predicted cell type proportions were compared to orthogonal RNAScope/IF measurements. Conclusions Bisque and hspe were the most accurate methods, were robust to differences in RNA library types and extractions. This multi-assay dataset showed that cell size differences, marker genes differentially quantified across RNA libraries, and cell composition variability in reference snRNA-seq impact the accuracy of current deconvolution methods.
Hey #deconvolution fans! 👀 We’ve got an exciting new pre-print for you: a benchmark of 6 popular deconvolution methods on a multimodal human brain #DLPFC dataset 🧠🧬 @LieberInstitute @jhubiostat #scitwitter
— Louise Huuki-Myers (@lahuuki) April 15, 2024
📎 https://t.co/4KXibeerZi pic.twitter.com/0O8E5emIeP
Louise A. Huuki-Myers
Research Associate 2020-2022, Staff Scientist I, Data Science 2022-ongoing, PhD Student 2024-ongoing
Nicholas J. Eagles
Research Assistant 2018-2021, Research Associate I 2021-2024, Research Associate II 2024-ongoing
Daianna Gonzalez-Padilla
LIBD Summer Intern 2022, Intern 2022-ongoing
Leonardo Collado-Torres
Investigator @ LIBD, Assistant Professor, Department of Biostatistics @ JHBSPH
#rstats @Bioconductor/🧠 genomics @LieberInstitute/@lcgunam @jhubiostat @jtleek @andrewejaffe alumni/@LIBDrstats @CDSBMexico co-founder